
Alors que 2019 s’achève, la croissance américaine sera positive pour la dixième année consécutive, faisant de cette expansion la plus longue depuis le milieu du XIXème siècle ! Ces dernières années, l’inhabituelle longueur de ce cycle a régulièrement poussé les Cassandre à s’inquiéter de l’imminence d’une récession. Avec un raisonnement simple – plus l’expansion se prolonge, plus le risque qu’elle cesse augmente – mais erroné : comme le relevait Janet Yellen voici quelques années, « les expansions ne meurent pas de vieillesse ».
Cette année toutefois, les craintes d’une récession aux Etats-Unis n’ont pas été seulement alimentées par ce risque d’un « épuisement » du cycle. Elles se sont également nourries des tensions commerciales, du ralentissement de l’activité en Chine et dans le reste du monde, ou encore de la montée des incertitudes géopolitiques. La persistance de ces menaces, l’apparition de risques nouveaux et l’exceptionnelle longévité de ce cycle ont toutes les chances de raviver la crainte d’une récession en 2020.
Si l’analyse macroéconomique classique permet d’identifier les sources d’instabilité (accumulation de déséquilibres macroéconomiques, existence de bulles de prix d’actifs…) et les chocs susceptibles de faire basculer une économie en récession (guerre commerciale, politique monétaire trop restrictive…), elle ne permet pas de donner une mesure « objective » de ce risque. Pour y remédier, les économistes et les gérants quantitatifs de Candriam ont développé des indicateurs quantitatifs propriétaires.
Longtemps, leur construction s’est appuyée sur des modèles de type « probit » : dérivés des modèles de régressions linéaires, ces modèles sont utilisés lorsque la variable à expliquer est binaire. Ils permettent d’estimer la probabilité de réalisation d’un des deux événements, en l’occurrence ici, la probabilité qu’une récession survienne (ou non) à un horizon donné. A l’usage, ces modèles souffrent toutefois d’un défaut important : des modèles ayant une qualité statistique équivalente sur le passé peuvent conduire à des prévisions de probabilité de récession très différentes. Le choix des variables explicatives joue ici un rôle déterminant et biaise fortement les prévisions.
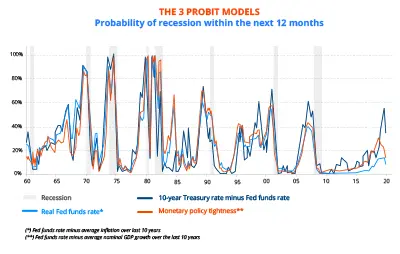
L’estimation de trois modèles « probit » reposant surtout sur la pente de la courbe des taux d’intérêt illustre cette fragilité. Alors que par le passé, pente de la courbe, taux court réel et degré de restriction de la politique monétaire se révélaient des indicateurs également fiables de l’imminence d’une récession aux Etats-Unis, les signaux envoyés depuis quelques années divergent… Faute de connaître le « bon » modèle, le choix de l’une ou l’autre de ces variables explicatives – dont les évolutions sont pourtant voisines – risque de conduire à une mauvaise appréciation du risque de récession.
GRAPHIQUE 1 : les 3 modèles « probit »
Pour pallier cette difficulté, des méthodes plus sophistiquées – et plus robustes ! – peuvent être utilisées. Deux idées sous-tendent ces approches :
- « C’est en forgeant que l’on devient forgeron » : autrement dit, rien n’est acquis, c’est en entraînant des modèles sur des jeux de données différentes qu’on les perfectionne et que l’on augmente leur capacité prédictive.
- La « sagesse des foules » ou l’intelligence collective : la diversité d’opinions, leur indépendance et leur agrégation (par opposition au choix discrétionnaire de l’une de ces opinions) conduisent une « foule » à être collectivement plus intelligente que n’importe lequel des individus qui la composent. Transposée au cas qui nous intéresse, cette « sagesse des foules » conduit à préférer l’agrégation des informations fournies par une multitude de modèles à l’information issue de n’importe lequel d’entre eux. Autrement dit, il est vain de rechercher le meilleur modèle sur le passé puisqu’il n’y a aucune garantie qu’il le reste à l’avenir. Il est donc préférable de combiner une grande diversité de modèles pour en extraire une information « moyenne » plus fiable.
Nous avons développé deux méthodes dont nous présentons ici brièvement les résultats. Celles-ci ont été développées en retenant un échantillon d’une centaine de variables économiques et financières susceptibles d’expliquer la survenue d’une récession à l’horizon d’un an.
Première méthode : « Bayesan averaging of probit models »
Cette méthode repose sur l’estimation de plusieurs centaines de milliers de modèles « probit » combinant jusqu’à quatre variables explicatives, parmi lesquels seuls une dizaine de milliers de modèles ayant un sens du point de vue économique ont été retenus. Tel un chirurgien qui, à la veille d’une opération délicate, doit prendre une décision fondée sur l’interprétation qu’il fait d’un cliché radiologique, les modèles sont évalués en tenant compte de l’incertitude liée à l’apparition de nouvelles circonstances. En d’autres termes, chaque modèle est évalué en terme probabiliste. Grâce à la règle de Bayes, la combinaison des modèles permet d’obtenir une probabilité de récession construite d’après un raisonnement rationnel en présence d’incertitude.
Deuxième méthode : les forêts aléatoires
Les forêts aléatoires sont un ensemble aléatoire d’arbres de décision. L’idée d’un arbre de décision est de découper l’espace des variables en groupes homogènes, autrement dit de sélectionner les variables (et leur niveau) successivement afin de classer au mieux les événements qui nous intéressent (une récession aura lieu d’ici un an… ou pas).
Contrairement aux modèles « probit », les « arbres de décisions » sont des méthodes non paramétriques qui permettent de prendre en compte une plus grande complexité d’interactions entre les variables. Leur utilisation a toutefois longtemps été freinée en raison de leur instabilité : une légère modification des données entraîne la construction d’arbres très différents… et donne donc des prévisions elles aussi très différentes !
L’association de l’idée de « sagesse des foules » aux avancées en matière d’intelligence artificielle – plus précisément de « machine learning » – a, depuis le début des années 2000, permis l’émergence d’un algorithme qui pallie cet inconvénient : les forêts aléatoires d’arbres décisionnels. Comme ce nom l’indique, cette approche s’appuie non pas sur la recherche d’un seul arbre, mais sur l’agrégation d’une multitude d’arbres (une forêt) pour, là encore, réduire la variance et le biais des prévisions.
La réduction de la variance est également assurée par la mise en place d’un processus d’apprentissage de l’algorithme sur des sous-périodes (c’est là que le forgeron entre en jeu !) et la confrontation des prévisions à la réalité observée en dehors de ces périodes d’apprentissage.
GRAPHIQUE 2 : RF et Bayesian averaging
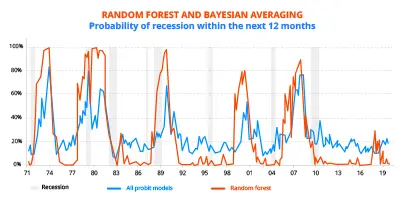
Ces deux méthodes donnent aujourd’hui une probabilité de récession à 12 mois aux Etats-Unis relativement faible. Le Bayesian averaging la situe autour de 20 %, en légère hausse depuis fin 2017. Les forêts aléatoires d’arbres décisionnels donnent un résultat plus tranché encore puisque, après être montée vers 20 % entre fin 2017 et fin 2018, cette probabilité est aujourd’hui quasiment nulle. L’analyse quantitative que nous avons développée conforte donc notre conviction d’économistes : malgré le ralentissement à l’œuvre, les Etats-Unis ne devraient pas connaître de récession en 2020 (cf. article sur les perspectives 2020 du 2 décembre).
